Uživatelský manuál
Stručný průvodce
Dashboard
Přehledy
Detail případu (Caseoverview)
Případ - Událost
Úkoly
Poznámky případu
Dokumenty
Nastavení uživatele
Oblíbené
Komponenta tabulky
FAQ
Novinky/Oznámení v Team assistant
Nastavení mobilní aplikace
Admin dokumentace
Platforma
Administrace
Crony
Autentizace a synchronizace
Nastavení mobilní aplikace pro vaše prostředí
Schéma
Dynamické tabulky
Archivace
Skripty
Licence
Servisní konzole
Naplánované úkoly
HR Agenda
Sekvence
CSP hlavičky - zásady zabezpečení obsahu
Logy
Správa novinek (Notifikační centrum)
Nastavení přístupového tokenu a vypršení platnosti relace
Šablona
Role
Self-hosted administration
Plánování
Uživatelé
Organizační struktura
Události
Překlady
NFC integrace
AXIOS API
AXIOS s využitím Trezoru
Axios s využitím certifikátů (SSL)
Výpočty a funkce
Integrace
TAS Forms
Pokročilé funkce a tipy
Filtrování v dynamickém listu pomocí URL parametru (statické)
Optimalizace přehledů s velkým počtem případů
AI Features
Produkt
Technický changelog
Business Changelog
Průvodce upgradem z předchozích verzí
Upgrade na 5.17
Upgrade na 5.7
Lodash upgrade v4.17.x (>v5.5)
Hlavní změny a zaniklé funkce (v5.3 > v5.7)
Podbarvení proměnných ve stavu Read-only (>v5.7.58)
Použití validačních funkcí
Upgrade na 5.3
Migrace dynamických podmínek
Úprava a kontrola tisku pdf
Úprava Popis úkolu vs Instrukce k úkolu
Transpilace forEach na for loop
Vykreslení HTML na Caseoverview
Rozdíly mezi TAS4 a TAS5 - kompletní přehled
Best Practices upgrade z TAS 4 na TAS 5
Technické požadavky a architektura
Status routes
Prerekvizity serveru
Bezpečnost a ochrana dat
Security
TAS Operations Runbook
Technologická architektura
Graceful Shutdown + Status Routes
Aktuality / Důležité informace
Getting Started
- Vše /
- Admin dokumentace
- Pokročilé funkce a tipy /
- Optimalizace přehledů s velkým počtem případů
Optimalizace přehledů s velkým počtem případů
V rámci procesů s velkým počtem případů (desítky tisíc) je vhodné přehledy optimalizovat, aby se předešlo velké zátěži databáze a výsledky vyhledávání byly rychlejší.
1. Filtrování přehledů na hlavičku
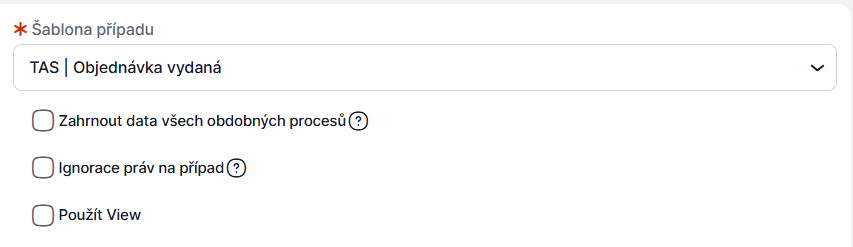
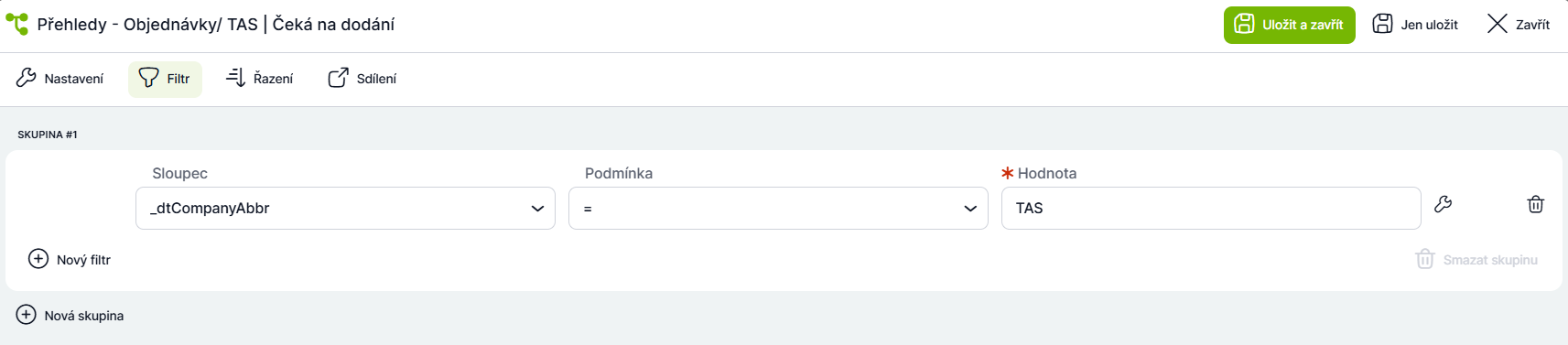
V případě, že jsou přehledy rozlišovány podle společností (jedna šablona slouží pro více společností), je vhodné provádět filtrování pomocí hlavičky, nikoliv pomocí proměnné:
Správná varianta:
Nevhodná varianta:
2. Řazení podle data vytvoření případu
Nejrychlejších výsledků lze dosáhnout, pokud jsou přehledy řazeny sestupně podle data vytvoření případu.

Ostatní způsoby řazení, např. podle textové proměnné _iprocId nebo podle čísla objednávky, jsou při velkém množství dat výrazně náročnější, jelikož se většinou jedná o textové proměnné.
3. Rozdělení přehledů podle roku
V rámci vyhledávání se ve většině případů (cca 99 %) pracuje maximálně s daty za poslední dva roky. V takovém případě je vhodné vytvořit přehled „Aktuálních“ případů, kde může být nastaven například následující filtr:
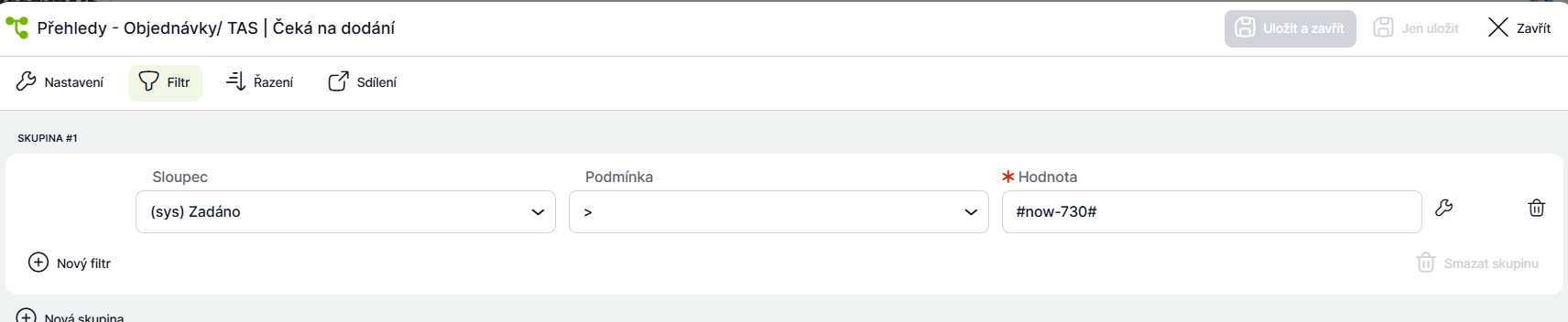
Ostatní případy, které jsou starší, lze přesunout do samostatné složky, kterou můžeme nazvat „Archiv“, a filtr v ní nastavit opačně.
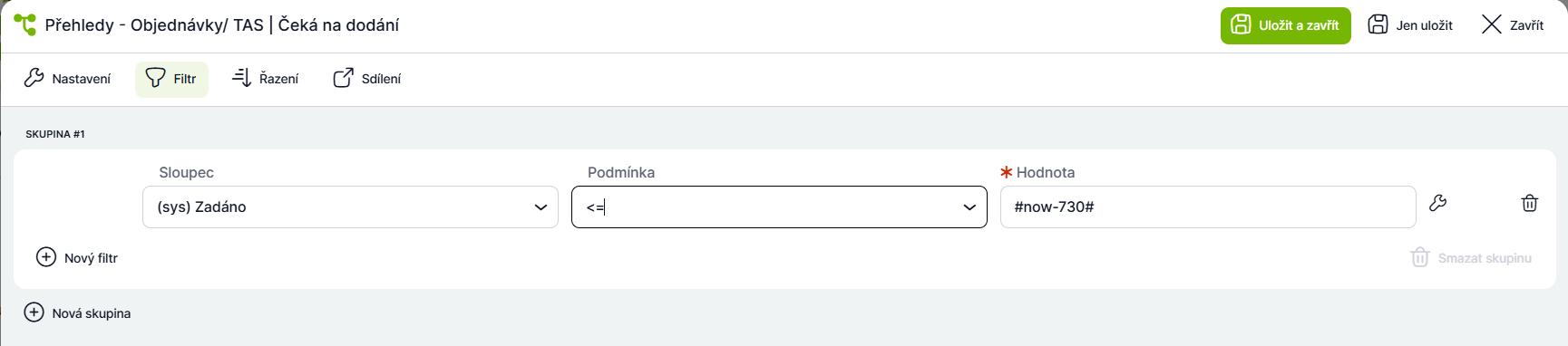
4. Přehledy s hodně případy nedávat na Dashboard
Na Dashboard lze vložit konkrétní přehledy, ale v případě, že nejsou dostatečně zafiltrovány, je dotaz do databáze velmi náročný a negativně ovlivňuje výkon. Na Dashboardu obvykle postačí filtrovaná množina případů, například Neschválené objednávky apod. Případně lze dát do Oblíbených odkaz na konkrétní přehled.
